Empowering Innovation with
Intelligent
Solutions
Welcome to PIRUN, where innovation and expertise converge. As a leading software development team, we pride ourselves on our diverse capabilities, spanning backend development, frontend design, mobile application creation, and cutting-edge AI solutions
View Projects0+
Succeeded
Projects
0
Working
Hours
0+
Years
Experience
0+
Active
users
Instance Segmentation
Our team excels in identifying and delineating individual objects within an image, providing precise boundaries for each instance. For example, in a scene with multiple people, we can accurately segment each person from the background and determine their exact outlines. We employ techniques like Region-based Convolutional Neural Networks (R-CNN), Faster R-CNN, Mask R-CNN, and DeepLab to achieve this.

R-CNN:
A two-stage approach that first generates region proposals and then classifies and regresses bounding boxes for each proposal.
Mask R-CNN
An extension of Faster R-CNN that adds a branch for instance segmentation, predicting a pixel-wise mask for each detected object.
Faster R-CNN:
An improved version of R-CNN that introduces a Region Proposal Network (RPN) to efficiently generate region proposals.
DeepLab
A fully convolutional network that uses atrous convolution and dilated convolutions to capture multi-scale information and achieve high-resolution segmentation.
Semantic Segmentation
We specialize in categorizing every pixel in an image into meaningful semantic classes, enabling detailed scene understanding. This allows us to distinguish between different objects and their attributes, such as cars, pedestrians, roads, and buildings. We utilize techniques such as Fully Convolutional Networks (FCNs), U-Net, DeepLab, and PSPNet for semantic segmentation.

FCNs
A fully convolutional network that replaces fully connected layers with convolutional layers, allowing for end-to-end training and dense pixel-wise predictions.
U-Net
An extension of Faster R-CNN that adds a branch for instance segmentation, predicting a pixel-wise mask for each detected object.
DeepLab
A fully convolutional network that uses atrous convolution and dilated convolutions to capture multi-scale information and achieve high-resolution segmentation..
PSPNet
A pyramid scene parsing network that incorporates a pyramid pooling module to capture context at different scales.
Object Detection
Our expertise lies in locating and classifying objects within images or videos, providing accurate bounding boxes and labels. This enables us to identify and track objects of interest, such as vehicles, faces, or animals. We employ techniques like YOLO, SSD, Faster R-CNN, and RetinaNet for object detection
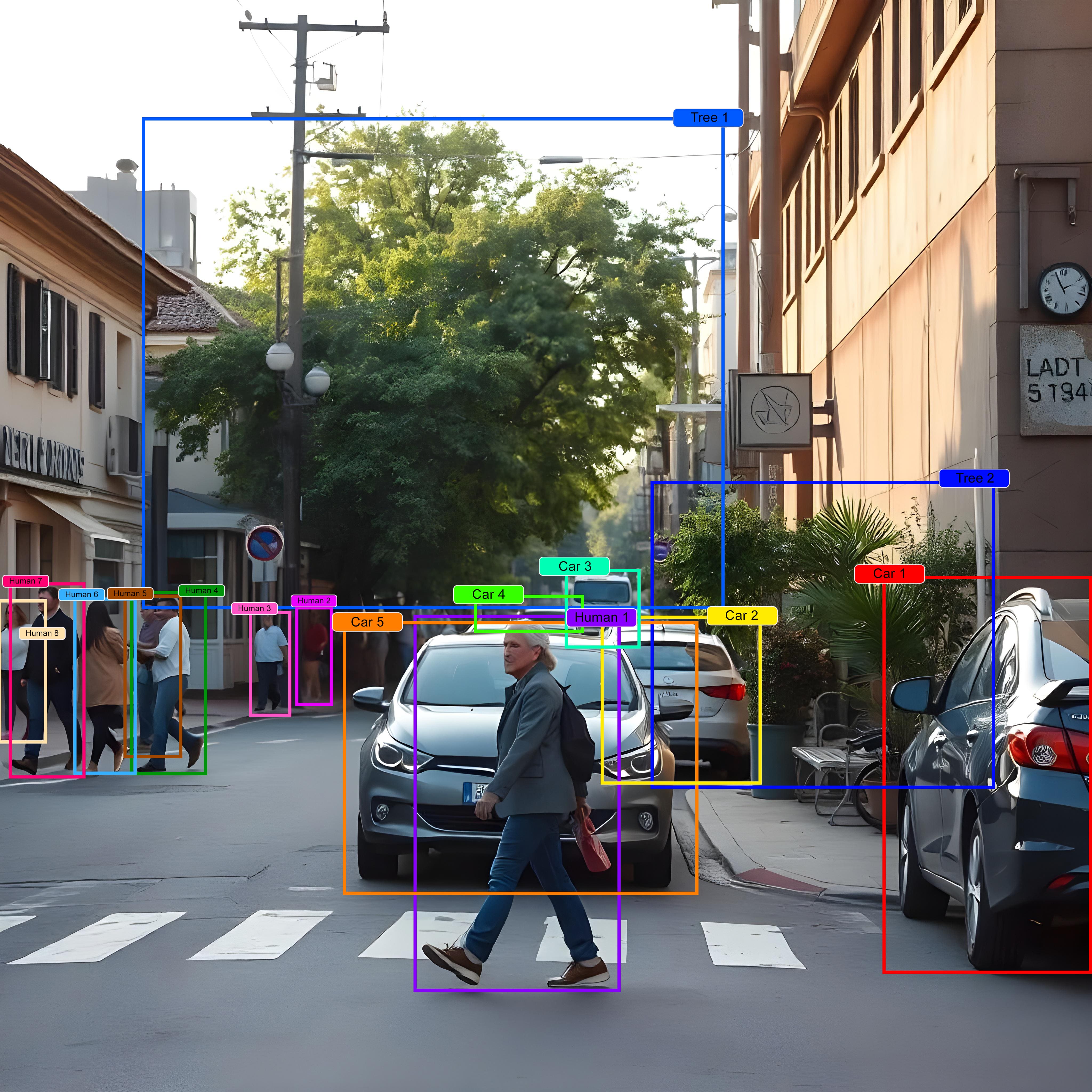
YOLO
A one-stage detector that divides an image into a grid and predicts bounding boxes and class probabilities for each cell.
SSD
A single-shot detector that uses multiple feature maps at different scales to detect objects of various sizes
Faster R-CNN
A two-stage detector that uses a Region Proposal Network (RPN) to efficiently generate region proposals
RetinaNet
A one-stage detector that uses a focal loss function to address class imbalance and improve detection accuracy.
Depth Estimation
We can accurately determine the distance between objects and the camera in a scene, creating a 3D representation from 2D images. This is useful for applications like autonomous driving, augmented reality, and robotics, where understanding the spatial layout of a scene is crucial. We utilize techniques such as stereo matching, monocular depth estimation, and structure from motion for depth estimation.
Stereo matching
A technique that compares corresponding pixels in two images taken from different viewpoints to estimate depth.
Monocular depth estimation
A technique that estimates depth from a single image using cues like occlusion boundaries, vanishing points, and texture gradients
Structure from motion
A technique that reconstructs 3D structure from a sequence of images by estimating camera motion and object motion
Depth Estimation
Our algorithms can reliably follow and identify objects across multiple frames, enabling continuous tracking and analysis. This is essential for tasks such as surveillance, video analytics, and human-computer interaction. We employ techniques like Correlation Filter Tracking, Kalman Filter, and Deep Learning-based tracking for object tracking.
Correlation Filter Tracking:
A tracking algorithm that uses correlation filters to efficiently track objects in video sequences.
Kalman Filter
A probabilistic framework for estimating the state of a dynamic system from noisy measurements.
Deep Learning-based tracking
Tracking algorithms that use deep learning models to learn appearance features and motion patterns of objects
Classification
We can categorize images or videos into predefined classes, providing accurate and efficient labeling. This is useful for tasks like image sorting, image search, and medical image analysis. We employ techniques such as Convolutional Neural Networks (CNNs), Support Vector Machines (SVMs), and Random Forests for classification.
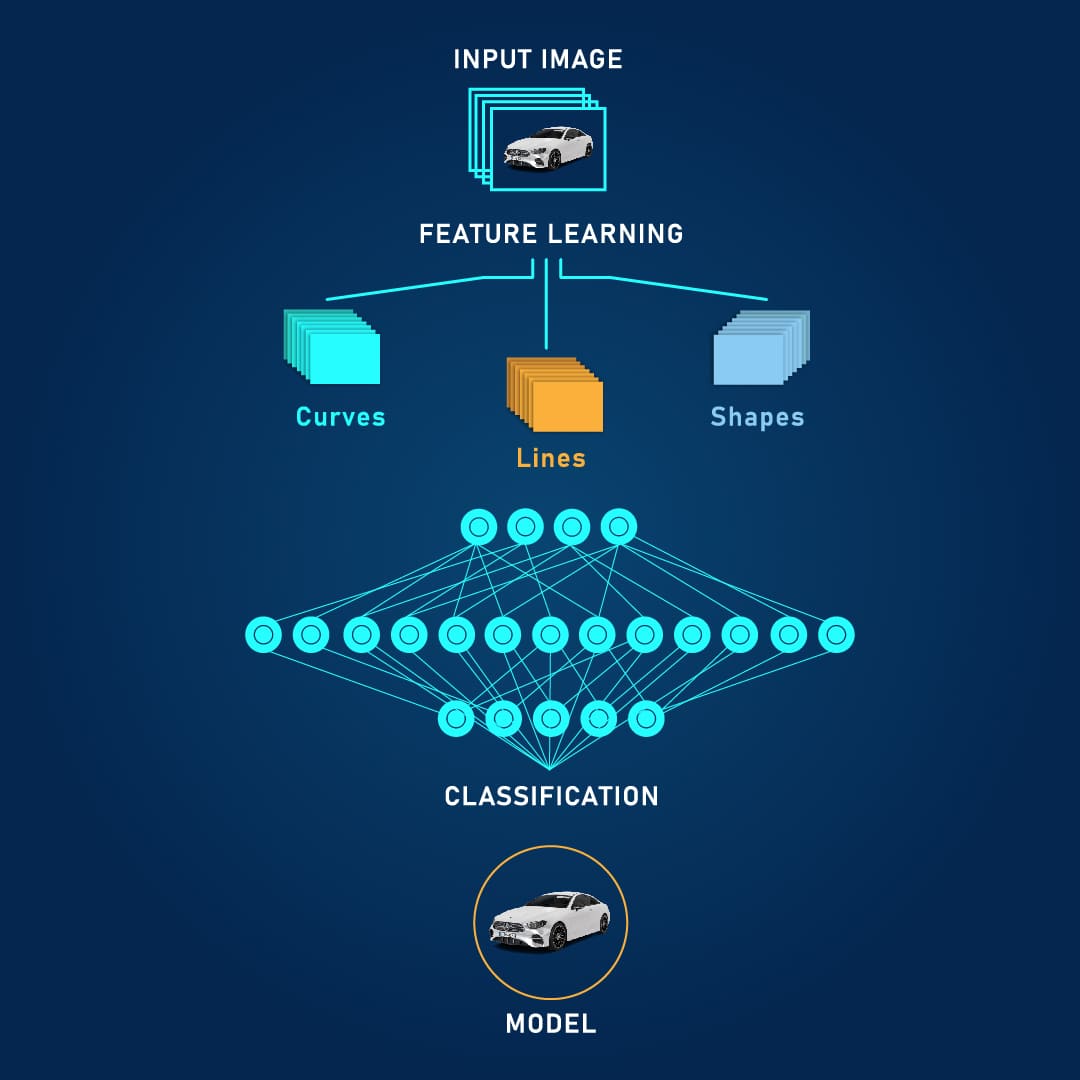
CNNs
Neural networks that are specifically designed for processing image data, featuring convolutional layers, pooling layers, and fully connected layers.
SVMs
Machine learning algorithms that find a hyperplane to separate data points into different classes.
Random Forests
Ensemble learning algorithms that combine multiple decision trees to make predictions.
Regression
Our models can predict continuous numerical values, such as object attributes or measurements. For example, we can estimate the size of an object, its speed, or its orientation. We utilize techniques such as linear regression, neural networks, and random forests for regression.
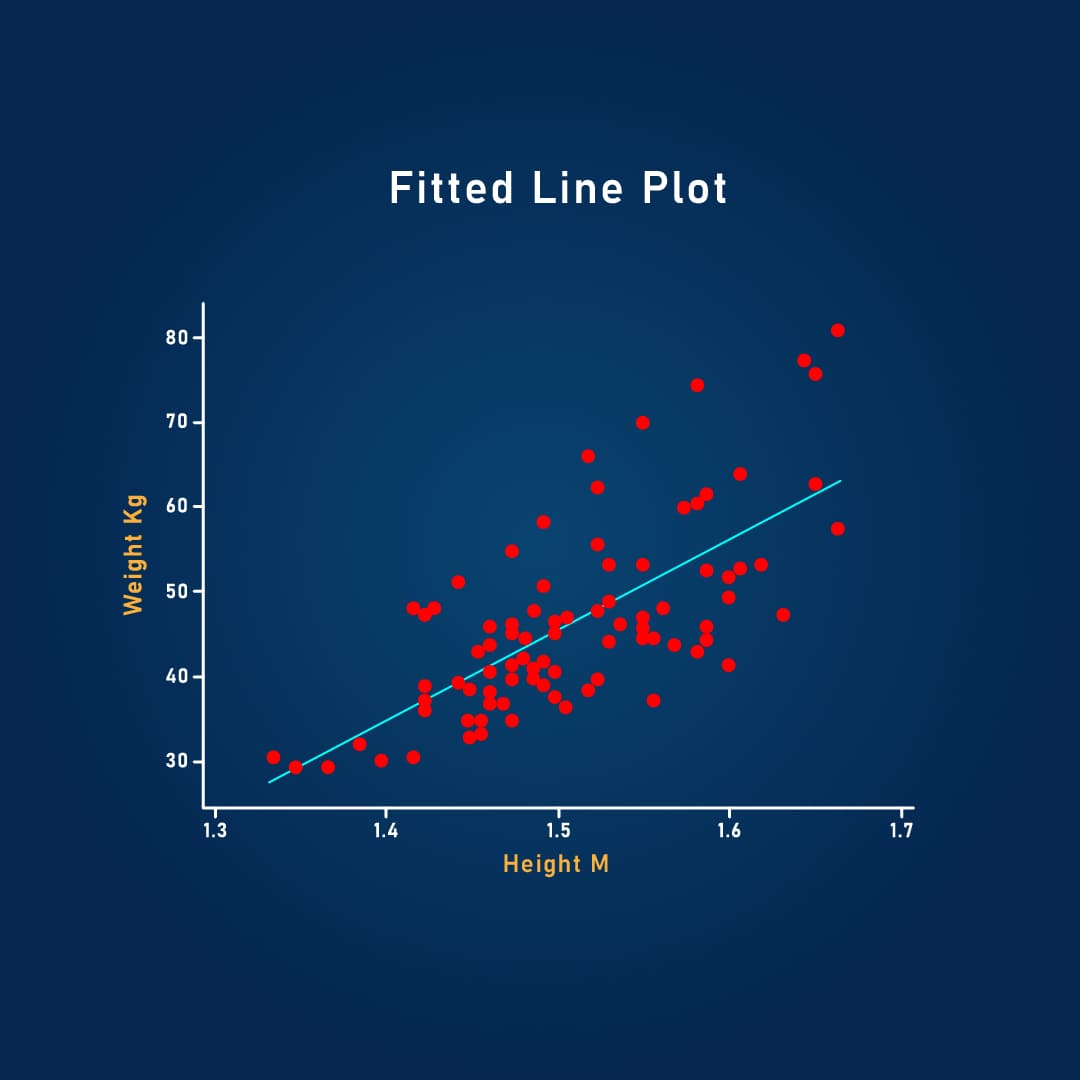
Linear regression
A statistical method that models the relationship between a dependent variable and one or more independent variables as a linear equation.
Neural networks
A class of machine learning models that are inspired by the structure and function of the human brain
Random forests
Ensemble learning algorithms that combine multiple decision trees to make predictions

AI domains
Our Commitment
At PIRUN, excellence and innovation are at the heart of everything we do. We are dedicated to pushing the boundaries of technology, delivering solutions that not only meet but exceed our clients' expectations. Whether you need a reliable backend system, a stunning frontend design, a powerful mobile app, or an advanced AI solution, our team is here to make your vision a reality.
Optimization
Optimization improves software performance and resource use by refining algorithms and system components
Flexibility
Flexibility allows the software to adapt to changes in requirements and user needs, accommodating modifications and upgrades easily
Efficiency
Efficiency is the software's ability to perform tasks quickly and with minimal resources, enhancing performance and reducing costs
Reliability
Reliability is the software's consistency in performing its functions without failure, ensuring dependable and predictable performance
This is How Magic Happens
High Efficiency
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore aliqua.
Team of Experts
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore aliqua.
Technology
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore aliqua.